HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors
NeurIPS 2024
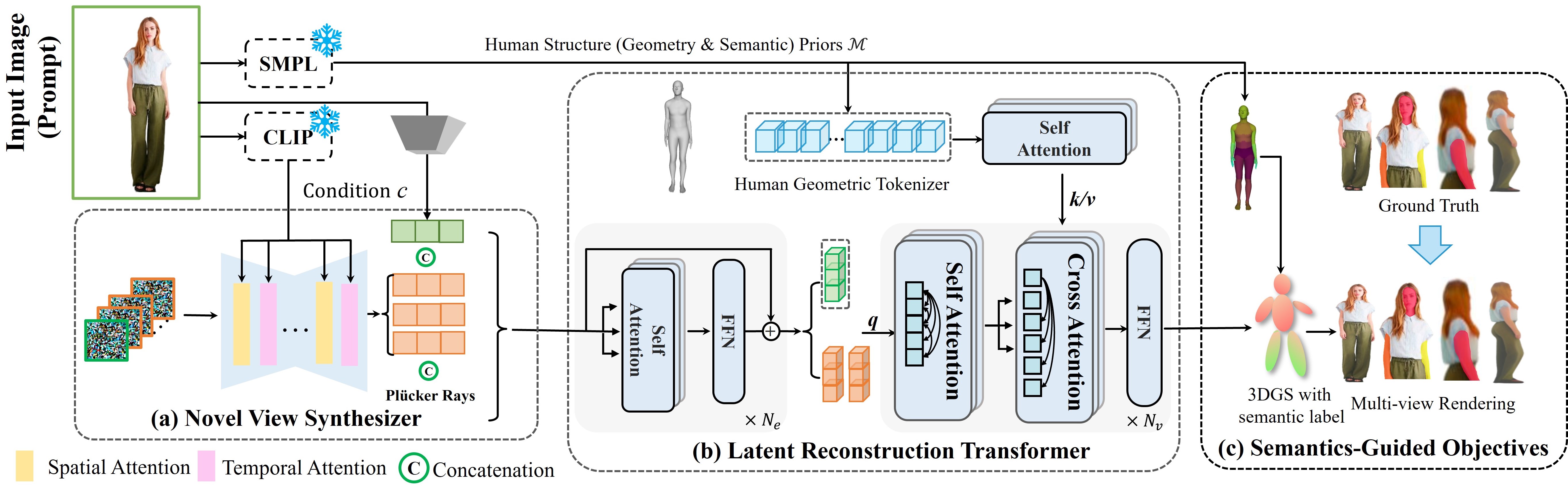
Abstract
Despite recent advancements in high-fidelity human reconstruction techniques, the requirements for densely captured images or time-consuming per-instance optimization significantly hinder their applications in broader scenarios. To tackle these issues, we present HumanSplat that predicts the 3D Gaussian Splatting properties of any human from a single input image in a generalizable manner. In particular, HumanSplat comprises a 2D multi-view diffusion model and a latent reconstruction transformer with human structure priors that adeptly integrate geometric priors and semantic features within a unified framework. A hierarchical loss that incorporates human semantic information is further designed to achieve high-fidelity texture modeling and better constrain the estimated multiple views. Comprehensive experiments on standard benchmarks and in-the-wild images demonstrate that HumanSplat surpasses existing state-of-the-art methods in achieving photorealistic novel-view synthesis.
Novel View Synthesis

Comparsion
Related Links
SIFU (CVPR'24) is capable of reconstructing a high-quality 3D clothed human model, making it well-suited for practical applications such as scene creation and 3D printing.
TeCH (3DV'24) reconstructs the 3D human by leveraging descriptive text prompts (e.g., garments, colors, hairstyles) which are automatically generated via a garment parsing model and Visual Question Answering (VQA), a personalized fine-tuned Text-to-Image diffusion model (T2I) which learns the "indescribable" appearance.
GTA (NeurIPS'23) is a novel transformer-based architecture that reconstructs clothed human avatars from monocular images.
BibTeX
If you find our work helpful, please consider citing:
@inproceedings{pan2024humansplat,
title={HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors},
author={Pan, Panwang and Su, Zhuo and Lin, Chenguo and Fan, Zhen and Zhang, Yongjie and Li, Zeming and Shen, Tingting and Mu, Yadong and Liu, Yebin},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2024}
}